Machine Learning for Transport Mode Classification
This fall I encountered the quite interesting problem of inferring what mode of transportation a person is using based on sensor data. The context for this was my smart energy course. The course is broadly about using ICT to enable sustainable energy usage and one of our assigned projects was to develop an android app to let people track their daily energy usage from transportation. For this me and my group trained a classifier based on speed measurements from the smartphone GPS.
There is plenty of research on this topic and I don’t claim to provide a complete coverage of the area. See this rather as a short introduction to an interesting application of machine learning. For a more academic resource I refer to this great review paper by Nikolić and Bierlaire.
The Problem of Transport Mode Classification
Transport mode classification is the problem of based on some data classifying what mode of transportation a person is currently using. In this setting that data mainly comes from a carried smartphone. How specific the classification should be can be different in different applications, but some categories generally considered are:
- Walking
- Bicycle
- Car
- Bus
- Tram
- Train
Sometimes groups of these are considered, for example motorized or not.
Sensors and Data
Typically data from smartphone sensors is used. This makes sense since most people would already carry their smartphone while traveling. Some type of specialized hardware could however also be considered.
The main pieces of data used are speed and acceleration, based on position measurements. Speed and acceleration can be estimated from numerical differentiation of position, but one can consider using for example an accelerometer to measure acceleration more accurately. The position can be retrieved from the GPS module of a smartphone. Note that the absolute position (position on earth) is a poor feature choice since it would require training on data from every exact location the system should function at.
External data can also be used to improve predictions. One way to make position data useful is to combine it with public transport maps and timetables. By comparing the user’s position with trajectories of trams, buses and trains these modes could easily be classified. Note that this requires (real-time) web APIs for public transport routes. Some other ways to bring more data into the prediction is to compare movements to other users or earlier trips. Taking past trips into account leads to an extension of the classification problem to also infer travel patterns. I do not intend to discuss this further here, but this is an interesting problem in its own right.
Machine Learning Approaches
There are two main approaches to learning a classifier for transport modes. The first is to treat the previously mentioned data as a time series and directly feed this to the classifier. The input data then has a time-dimension of varying length and (dependent on exactly what is measured) one or more channels at each time-step. At least the speed at each time-step would be included in such an approach. In this group we find Hidden Markov Models, which is one of the most popular approaches to this problem. Another, maybe more modern, approach is Artificial Neural Networks. The typical approach to time-series classification with ANNs is using a recurrent network and LSTM units. The neural network approach is much more rare, but could be an interesting future project.
The second main approach to the problem is to first extract features from the raw data. This opens up to a larger family of possible machine learning models since the data no longer has the shape of a time-series. Features extracted here are generally different statistical properties of the speed or acceleration throughout one trip. Common models used are decision trees, K nearest neighbor and support vector machines.
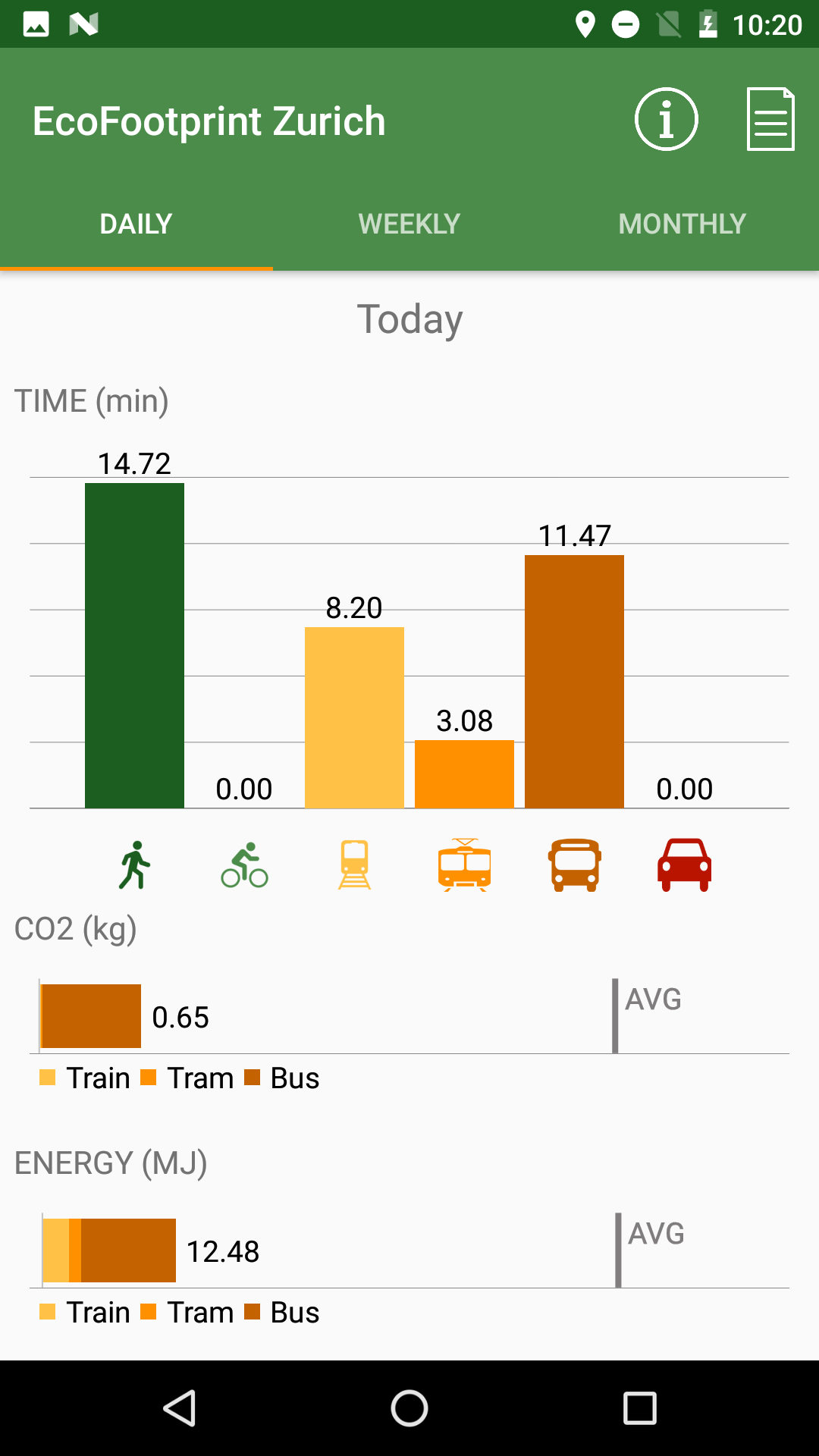
My Solution
For my course project I took the main responsibility of training our classifiers. We were handed a small dataset which we had helped out collecting and labeling earlier. Because of limited time I chose to go with the second of the approaches discussed earlier and extracted a set of features from each trip to be classified.
The features I used was inspired mainly by Zong et al., with the difference that I chose not to use acceleration in the final classifier. I did some experimenting with features based on acceleration, but it didn’t lead to any substantial increase in accuracy on validation data. The features used were:
- Trip length
- Average speed
- Maximum speed
- Standard deviation of speed
- 25, 50 and 75 percentiles of speed

My workflow was based in two Python scripts. One for extracting features and one to validate models. I tried a multitude of models and hyperparameters, including:
- Random forests
- SVMs with rbf-kernels
- k-nn classifiers
After removing some outliers I used k-fold cross validation to estimate generalization error of the different classifiers. After a bit of testing different models and tweaking hyperparameters I ended up with a random forest of 40 decision trees. This classifier had a balanced accuracy of ~80% on a 50-50 training-test split of the original dataset. Even though this is far from perfect I decided it was a good result given the data I had to work with. The classifier also showed good results when tested in practice on real trips.
The fact that the dataset I worked with was fairly small was a challenge. I considered trying out the neural network approach, but it is likely that the size of the dataset would had made it very hard to train a network sufficiently. A perhaps even bigger challenge was how unbalanced the dataset was. Some classes, such as car and train had very few data points. My approach to this was to apply the SMOTE algorithm for creating new, artificial samples from these classes. This gave a small increase in the balanced accuracy.
Another challenge of this project was that the classifier had to be part of the final app. Since android apps are built in Java (or alternatively Kotlin) the final model had to be in Java code as well. As Java isn’t the greatest language for machine learning my approach to this was to use Python and scikit-learn for training the model, but then porting the final classifier to Java by using sklearn-porter. This worked great and I would definitely recommend sklearn-porter to anyone who prefers working with Python, but needs to port their models to some other language. The only downside of this approach was that I had to recreate the code for feature extraction both in Python and Java. For me this highlighted how we can not train machine learning models in a vacuum and as soon as we reach a good accuracy be done. Models exist as part of bigger systems and making a model work together with other parts of the system is just as important as being statistically accurate.
There are a couple related problems that we avoided tackling thoroughly in this project. These include:
- Determining when trips start and stop
- Detecting when a building is entered.
- Real time updates of transport mode belief during trip
- Handling the many brief stops of public transport as one continuous trip.
Why is This Even Useful?
So what is even the use case for automatic transport mode classification? One possible use is exactly what my course project targeted, to give people a better understanding of energy and emissions form their transportation habits. Few people would probably be interested in such a service if it required constant manual labeling of all their trips. These sorts of decision helping systems have shown to impact users behavior and thereby save energy. The effect is even stronger if social norms are introduced, where users are compared to others.
More in general it is not hard to see that a dataset describing detailed transportation habits could be very valuable both for individuals and organizations that they choose to share it with. There are many great opportunities for research, urban planning, public transport etc.